
Java·JVM·JUC(三)
Java·JVM·JUC(三)
ThreadLocal 实现原理是什么?
ThreadLocal 是一个本地线程副本变量工具类,在每个线程中都创建了一个 ThreadLocalMap 对象,简单说 ThreadLocal 就是一种以空间换时间的做法,每个线程可以访问自己内部 ThreadLocalMap 对象内的 value。通过这种方式,避免资源在多线程间共享。
Entry对象中使用WeakReference来保存ThreadLocal,防止出现内存泄露的情况
这样是为了防止线程里面的ThreadLocal使用完毕了,但是线程还在运行,这时如果这个传递的对象很大,又不能被回收,可能造成OOM
自定义实现ThreadLocal
public class ThreadLocal<T> { |
可以完成ThreadLocal功能的,但是在性能上却不是最优的。毕竟多线程访问ThreadLocal的map对象会导致并发冲突,用synchronized加锁会导致性能上的损失。
因此,JDK7里是将values这个Map对象保存在线程中,这样每个线程去取自己的数据,就不需要加锁保护的
```java
public class Thread {ThreadLocal.ThreadLocalMap threadLocals = null;}
## 简述 CAS 原理,什么是 ABA 问题,怎么解决?
CAS 操作——Compare & Set,或是 Compare & Swap,现在几乎所有的 CPU 指令都支持 CAS 的原子操作。
> java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的(AtomicInteger,AtomicBoolean,AtomicLong)。
>
> cas 是一种基于锁的操作,而且是乐观锁。
>
> 乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加 version 来获取数据,性能较悲观锁有很大的提高。
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
### CAS的原理
拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
### ABA 问题:
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。从 Java1.5 开始 JDK 的 atomic包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
AtomicStampReference在cas的基础上增加了一个标记stamp(== version)
```java
//AtomicStampReference:
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
简述常见的工厂模式以及单例模式的使用场景
简单工厂模式
用来生产同一等级结构中的任意产品(对于增加新的产品,需要扩展已有代码)。
```java
public class CarFactory {// 方法一 public static Car getCar(String car){ if(car.equals("五菱")){ return new WuLing(); }else if(car.equals("特斯拉")){ return new Tesla(); }else { return null; } } // 方法二 public static Car getWuLing(){ return new WuLing(); } public static Car getTesla(){ return new Tesla(); }}public class Consumer {
public static void main(String[] args) { // 接口,所有实现类 // Car car=new WuLing(); // Car car2=new Tesla(); // car.name(); // car2.name(); Car car = CarFactory.getCar("五菱"); Car car2 = CarFactory.getCar("特斯拉"); car.name(); car2.name(); }}
- 工厂方法模式
- 用来生产同一等级结构中的固定产品(支持增加任意产品)。
- ```java
public interface CarFactory {
Car getCar();
}
public class TeslaFactory implements CarFactory {
public Car getCar() {
return new Tesla();
}}
public class WuLingFactory implements CarFactory {
@Override
public Car getCar() {
return new WuLing();
}}
public class Consumer {
public static void main(String[] args) {
Car car = new WuLingFactory().getCar();
Car car1 = new TeslaFactory().getCar();
car.name();
car1.name();
}}
抽象工厂模式
围绕一个超级工厂创建其他工厂。该超级工厂称为其他工厂的工厂。
```java
public interface Factory {Fridge createFridge(); AirConditioner createAirConditioner(); Fan createFan();}
public class MediaFactory implements Factory{
@Override public Fridge createFridge() { // TODO Auto-generated method stub return new MediaFridge(); } @Override public AirConditioner createAirConditioner() { // TODO Auto-generated method stub return new MediaAirConditioner(); } @Override public Fan createFan() { // TODO Auto-generated method stub return new MediaFan(); }}
## Java 常见锁有哪些?ReetrantLock 是怎么实现的?
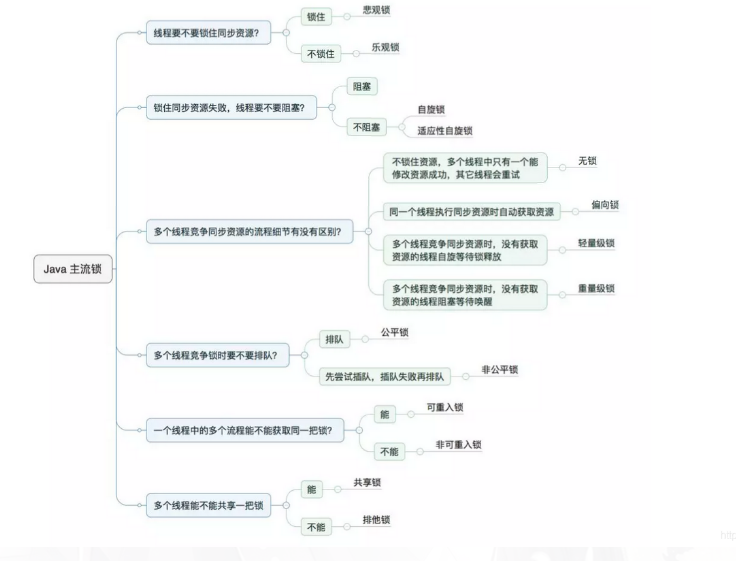
### ReetrantLock 是怎么实现的
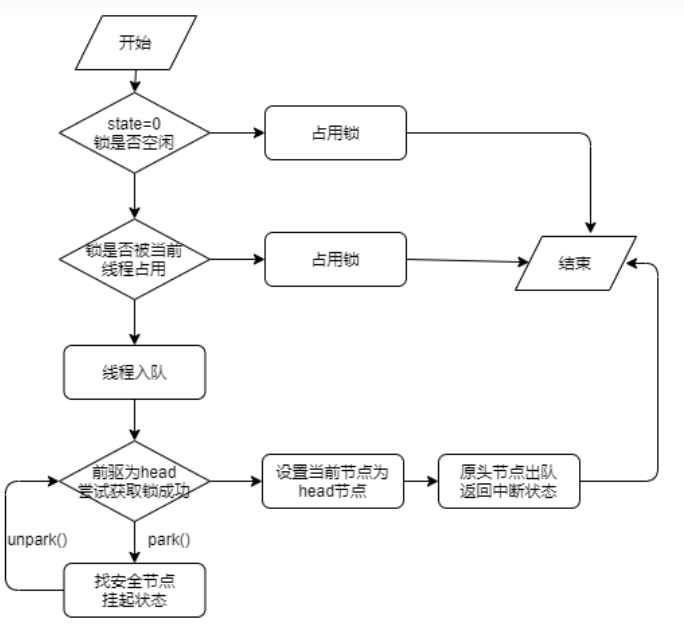
AQS:(AbstractQueuedSynchronizer)抽象的[队列](https://so.csdn.net/so/search?q=队列&spm=1001.2101.3001.7020)式同步器。即将暂时获取不到锁的线程加入到队列中。
**加锁**操作会对**state字段进行+1操作**,这里需要注意到AQS中很多内部变量的修饰符都是采用的[volitale](https://zhuanlan.zhihu.com/p/54327635),然后配合**CAS操作**来保证AQS本身的线程安全(因为AQS自己线程安全,基于它的衍生类才能更好地保证线程安全)。
这里的state字段就是AQS类中的一个用volitale修饰的int变量,state字段初始化时,值为0。**表示目前没有任何线程持有该锁**。
**当一个线程每次获得该锁时,值就会在原来的基础上加1,多次获锁就会多次加1**(指同一个线程),这里就是可重入。因为可以同一个线程多次获锁,只是对这个字段的值在原来基础上加1。
**相反unlock操作也就是解锁操作**,实际是是调用AQS的release操作,而每执行一次这个操作,**就会对state字段在原来的基础上减1**,当state==0的时候就表示当前线程已经完全释放了该锁。那么就会如上文提到的那样去调用“唤醒”动作,去把在“线程等待队列中的线程”叫醒。
## String 类能不能被继承?为什么?
不能被继承,因为String类有final修饰符,而final修饰的类是不能被继承的。
```java
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
// 省略...
}
HashMap 1.7 / 1.8 的实现区别
结构区别:
Jdk1.7
底层数据结构是数组加链表
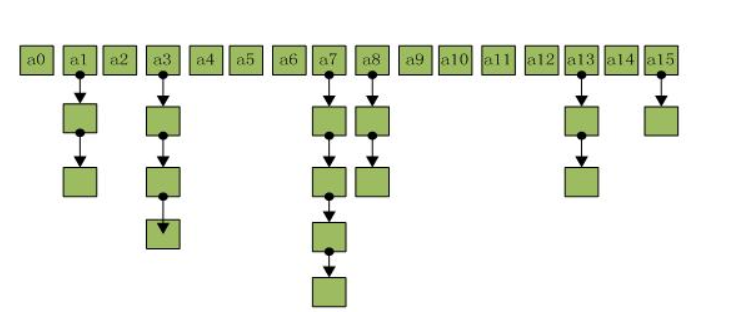
Jdk1.8
HashMap1.8的底层数据结构是数组+链表+红黑树。
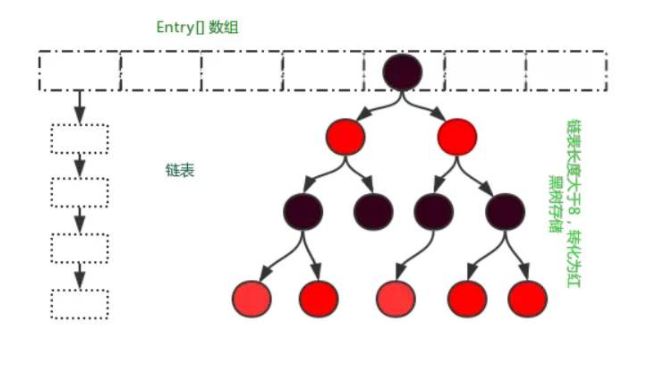
- 一般情况下,以默认容量16为例,阈值等于12就扩容,单条链表能达到长度为8的概率是相当低的,除非Hash攻击或者HashMap容量过大出现某些链表过长导致性能急剧下降的问题,红黑树主要是为了结果这种问题。
节点区别
Jdk1.8
- hash是final修饰,也就是说hash值一旦确定,就不会再重新计算hash值了。
- 新增了一个TreeNode节点,为了转换为红黑树。
Jdk1.7
- hash是可变的,因为有rehash的操作。
Hash算法区别
- 1.8计算出来的结果只可能是一个,所以hash值设置为final修饰。
- 1.7会先判断这Object是否是String,如果是,则不采用String复写的hashcode方法,处于一个Hash碰撞安全问题的考虑
对Null的处理
- Jdk1.7中,null是一个特殊的值,单独处理
- Jdk1.8中,null的hash值计算结果为0,其他地方和普通的key没区别。
初始化的区别
Jdk1.7:
- table是直接赋值给了一个空数组,在第一次put元素时初始化和计算容量。
- table是单独定义的inflateTable()初始化方法创建的。
Jdk1.8
- 的table没有赋值,属于懒加载,构造方式时已经计算好了新的容量位置(大于等于给定容量的最小2的次幂)。
- table是resize()方法创建的。
扩容的区别
Jdk1.7:
- 头插法,添加前先判断扩容,当前准备插入的位置不为空并且容量大于等于阈值才进行扩容,是两个条件!
- 扩容后可能会重新计算hash值。
节点插入
Jdk1.8:
- 尾插法,初始化时,添加节点结束之后和判断树化的时候都会去判断扩容。我们添加节点结束之后只要size大于阈值,就一定会扩容,是一个条件。
- 由于hash是final修饰,通过e.hash & oldCap==0来判断新插入的位置是否为原位置。
区别
- jdk1.7无论是resize的转移和新增节点createEntry,都是头插法
- jdk1.8则都是尾插法,为什么这么做呢为了解决多线程的链表死循环问题。
总结
| 比较 | HashMap1.7 | HashMap1.8 |
|---|---|---|
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 节点 | Entry | Node TreeNode |
| Hash算法 | 较为复杂 | 异或hash右移16位 |
| 对Null的处理 | 单独写一个putForNull()方法处理 | 作为以一个Hash值为0的普通节点处理 |
| 初始化 | 赋值给一个空数组,put时初始化 | 没有赋值,懒加载,put时初始化 |
| 扩容 | 插入前扩容 | 插入后,初始化,树化时扩容 |
| 节点插入 | 头插法 | 尾插法 |
题目答案均为转载,题目先后顺序按各大厂总出题次数排列!
此文章版权归Chankeitin所有,如有转载,请註明来自原作者
 wechat
wechat alipay
alipay






